~hackernoon | Bookmarks (1992)
-
NFT Paris 2025 Review: An Amazing Event, But Onboarding Normies? We’ve Got Work to Do
NFT Paris 2025 brought community and innovation to life, but onboarding struggles show Web3 still has...
-
IBM Researchers Create Mini AI Model That Predicts the Future
Researchers have developed a practical, efficient alternative to massive AI models for time series forecasting.
-
Reducing Server and Database Costs by 50% for an Insurance Broker using AWS
Hosting all services in a single public cloud and relying solely on credential protection can cause...
-
GraphQL is a Misunderstood Framework
GraphQL is an often misunderstood framework that went from being one of the most popular development...
-
Microsoft Researchers Identify 8 Core Security Lessons for AI
Microsoft AI Red Team releases whitepaper detailing lessons from its 100 generative AI products. Security researchers...
-
Mastering Response Compression Middleware in ASP.NET Core
This guide offers a comprehensive walkthrough of response compression in ASP.NET Core. It explores what is...
-
The HackerNoon Newsletter: How to Fit an Elephant in a Spreadsheet (2/20/2025)
How are you, hacker? 🪐 What’s happening in tech today, February 20, 2025? The HackerNoon Newsletter...
-
How to Build a No-Limits Stock Market Scraper with Python
Traditional stock market APIs come with rate limits and high costs, so I built my own...
-
Apex Fusion Launches PRIME Chain and AP3X Token, Bridging Bitcoin and Ethereum
Apex Fusion has launched its blockchain ecosystem with the AP3X token and PRIME chain, aiming to...
-
Why Crypto’s Future Depends on Fair and Transparent Token Distribution
Berachain’s BERA token launch has reignited debates over fair vs. VC-backed token distributions, as insiders dumped...
-
GitHub Actions Meets Kubernetes: How to Test PRs on GKE Without Losing Your Mind
I'm continuing my series on running the test suite for each Pull Request on Kubernetes.
-
People Lie. Even When They Think They’re Telling the Truth
Cognitive distortions are tricks our own brain sets for us. They can ruin our lives (and...
-
Web3 From The Eyes Of a Contributor
Web3 started in 2009 when Satoshi Nakamoto started the genesis block of Bitcoin. This article is...
-
Here's What No One Tells You About Launching a Crypto Startup
Trust is the deciding factor for the success of your startup in the crypto industry. Users...
-
A Historical Mathematical Concept Powers Information Retrieval In the Modern Age
Explore what, how and why cosine similarity plays a critical role in information retrieval/search systems.
-
Lead Product Designer Katarina Markina Talks About the Future and How Her Work Helps People
Katarina is a designer with 10+years of experience in the field. She is known for her...
-
Here's What the Pros Don't Tell You About Angular Unit Testing
In this article, I would like to share the experience I gained over the years with...
-
Why Some Data Sampling Methods Fail (And Others Don’t)
Fast-Coresets offer competitive compression with minimal distortion, outperforming BICO and Streamkm++. Uniform sampling is fast but...
-
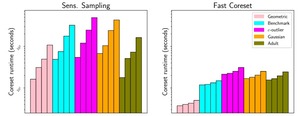
How Different Sampling Strategies Affect Clustering Accuracy
Fast-Coresets are compared against uniform sampling, sensitivity sampling, and state-of-the-art methods like BICO and Streamkm++ to...
-
What Is the Best Way To Compress Big Data Without Sacrificing Accuracy?
Fast-Coresets provide reliable compression for clustering but are slower than uniform sampling. Experiments analyze when fast,...
-
Reducing Spread Impact in Clustering Algorithms
By replacing log ∆ with log(log ∆), clustering computations become more efficient. A substitute dataset preserves...
-
How to Make Big Data Clustering Faster and More Efficient
Fast-kmeans++ and quadtree embeddings help compute coresets efficiently by quickly finding a rough solution. This reduces...
-
Coresets, Compression, and the Quest for Faster Data Clustering
We explore fast sampling methods for clustering, focusing on coresets that balance speed and accuracy. We...
-
How to Fit an Elephant in a Spreadsheet
Clustering large datasets is slow, but compressing data first can help. We propose a near-optimal method...