What’s the first thing you do when you open a PDF? Start reading the whole thing, or skim for the information you need? Unfortunately, Oscar’s nurses receive hundreds of unsearchable PDFs everyday — in fact, in the last 30 days, we have received more than 23,000 such documents. Because they’re unsearchable, these medical records or claims forms need to be read through in their entirety to find one piece of information that will allow them to help that member. No cmd + F for them. The quality of a lot of PDFs is, unsurprisingly, pretty bad and tough to read.
Knowing these text-heavy documents, would you really want to read through them to find one piece of information? Improving the efficiency and experience of our nurses who had to do this everyday inspired Oscar Engineering team’s DocStor OCR (optical character recognition) project. The goal of this project was to use OCR to make text from outside document PDFs (faxes, scans of letters, etc.) searchable from Chrome — a task especially relevant in a field, like health care, that still heavily relies on fax machines and other technology from the 1970s. The extracted text from these documents would then be stored into a database table for analytics purposes.
Wait a second, but really, how accurate is it?
We use Google Vision API after a comparison between Google vs. Amazon vs. Tesseract. Based on the tests we did, for printed text, its accuracy is above 98% (based on manual letter count comparison).
How we did this:
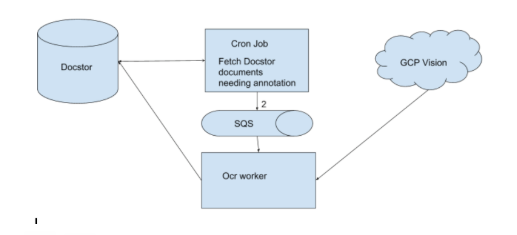
In order to backfill thousands of PDFs for historical documents and minimize manual retry and troubleshooting, we designed this simple, decoupled, self-retrying system.
In order to keep our design simple we kept SQS’s characteristics in mind and also took advantage of idempotence service:
- If a PDF OCR attempt fails because of a retriable error, including network failures, thrift timeout and google service unavailable error, the worker will just leave the message in SQS so it will be retried up to 5 times then falls to dead letter queue.
- But what happens if our dependent service is dead for more than a day? No worries, here’s the idempotence service to take effect. Before the cron job puts message (docstor_id) into the queue, it will propose the docstor_id to idempotence service with a 24 hr time-to-live (We choose 24 hr based on estimation that each PDF takes ~2 hr to retry). As a result, even if some PDFs cannot be processed in the next 24 hrs (with retriable error), they will be picked up the next day. Also, we picked the parameter here carefully to avoid duplication (even if duplication doesn’t really matter here).
Results:
We successfully finished backfilling all 2018 inbound PDFs in one month with eight OCR workers and now we are running real time with two workers. Eight workers could process roughly 10,000 PDFs per day, given an average document length of 10 pages (although the maximum we processed was 2,933 pages!), each of which takes seven seconds to process. The cost is 25 cents per 1,000 pages, and totally we spent $3,200 on backfilling 2018 PDFs.
Some result charts below show the cost daily and documents types we processed, beginning on July 13 and ending in early August:
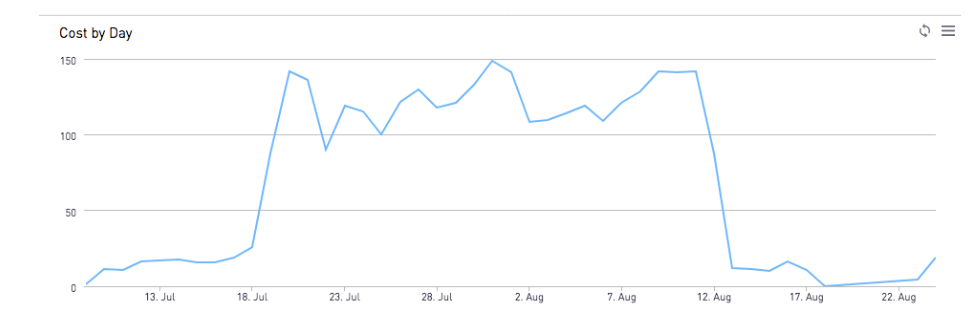
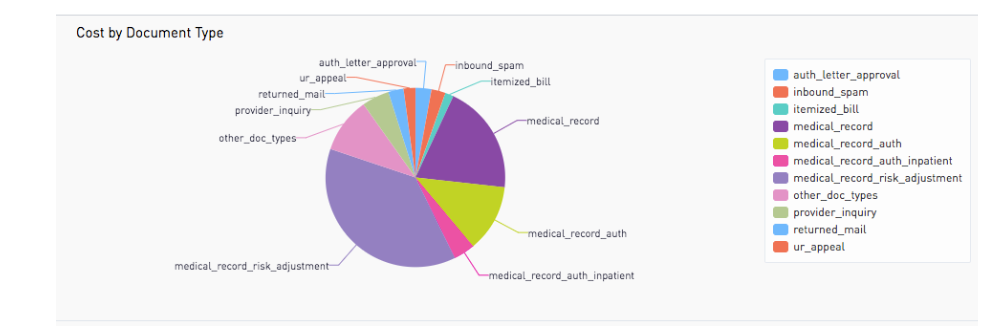
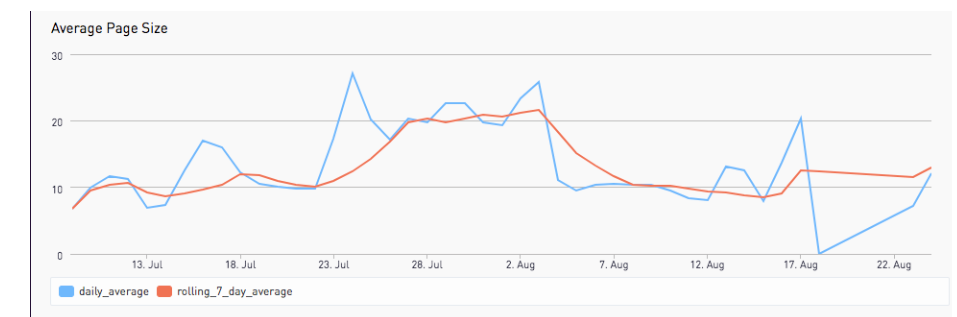
Some feedback from our nurses:
These results show that something seemingly simple — create a search function for a PDF — can have a profound impact on the day-to-day work of hundreds of employees, made clear by the feedback below:
“It’s been super beneficial for the nurses as it helps us save time on sifting through pages of clinicals and hone in on the information we really need.”
“When I read pages and pages of clinical and have to go back to something, I can just type in any key word I can recall and it helps spare me having to scroll back through hundreds of pages.”
“It’s great when we have hundreds of pages of clinical to review.”